
Co-author with Emilie Blum from OnlyDust.
Special thanks to Devansh Mehta from Ethereum Foundation for reviewing and for his pertinent questions that shaped up this article.
We manually allocated $10M to open source contributors. Then we trained an AI agent to do it better—using that data to evaluate contributions and distribute rewards at scale.
It worked. In just three rounds, the agent allocated $1M to over 2,000 devs with scoring accuracy that often beat human reviewers. We explain how we built it—step by step, with all the details.
But people found ways to game the system. So we had to shut the reward mechanism down. And found something even better. And yes, it is AI-powered.
At OnlyDust, we’ve seen it all—after two years supporting 450+ OSS projects, 8,000+ contributors, and manually distributing over $10 million in grants. Through that journey, we’ve tried a lot (and learned)—bounties, jury systems, maintainers acting as intermediaries.
It worked, but it didn’t scale.
Some efforts weren’t even worth the time investment.
Meanwhile, we were sitting on a goldmine: tens of thousands of contributions labeled in dollars by maintainers using their own budgets.
So we tried something bold. We trained an AI agent using that data to reward contributors directly.
“An agent to reward them all. And in the OSS, bind them.”— Greg, our CEO, probably under drugs.
It worked. In three rounds, the AI allocated $1M to over 2,000 contributors, often scoring with more consistency and precision than human maintainers. We thought we’d cracked the code on fair, scalable open source funding.
But rewarding pull requests with money brought new problems—gaming, misaligned incentives, and shallow contributions.
So we shut the reward engine down. But we kept the tech.
This is the story of what we built, what worked, what broke—and what comes next.
1 - The Bold Bet: Automating Fair Rewards
Instead of rewarding contributors based on promises or popularity, we wanted to reward real impact—what actually gets shipped and matters.
So we built an agent that looked at each pull request (PR) and figured out how valuable it really was. Our AI-based agent combined advanced language models, specialized prompts, and project-specific data to assess the complexity, quality, and scope of every contribution.
Contributors got paid monthly based on delivery—not on who they knew, how loud they were, or subjective guesswork.
How It Worked
1. Collect Data
We gathered detailed information from each PR made on GitHub: code changes, work type (feature, refactor, or documentation), time spent, communication quality with maintainers, and any related issues. These factors helped us evaluate both effort and potential impact.
2. AI Evaluation
Our agent then analyzed each PR using the latest language models to understand complexity, response to feedback, and whether the PR solved a key issue or introduced an important feature. It picked up subtle details—like code quality, thoughtful design, and testing practices.
3. Scoring Algorithm
After the AI completes its initial review, we calculate a single score using a multi-layered formula. Rather than relying on a simple sum, we incorporate factors like work complexity, impact on the project, and delivery quality in a more nuanced way. An example of our (simplified) formula looks like this:
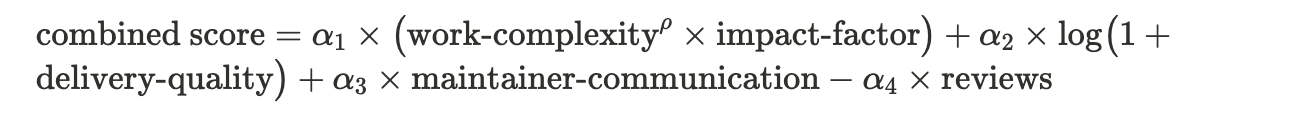
We then applied an additional transformation to reward standout contributions and ensure trivial work isn’t overcompensated (click for more info):
- Work Complexity and Impact Factor: We emphasize genuinely demanding tasks that solve important problems, raising complexity to a power and multiplying by an impact factor to highlight critical contributions.
- Logarithmic Delivery Quality: Responsiveness and thoroughness are crucial, but we use a logarithmic scale to prevent minor differences at higher quality levels from overshadowing significant PRs.
- Maintainer Communication: We reward contributors who maintain strong communication and alignment with project goals, reflecting the intangible benefits of smooth collaboration.
- Reviews: Excessive back-and-forth on major issues reduces the final score, motivating contributors to submit well-prepared PRs from the start.

4. Monthly Distribution
At the end of each month, we finalize payouts for every qualifying PR based on its overall score. PRs with minimal impact or trivial changes earn little or no reward, encouraging contributors to make meaningful contributions.
5. Less Work For Maintainers. More Work For Us
Maintainers just reviewed PRs for quality. No awkward reward allocation. We reviewed scores and feedback each month, adjusting when needed. The model kept learning.
2. Keeping It Fair: Safeguards
Automation doesn’t mean we leave contributors or maintainers stranded. We’ve introduced some safeguards to keep things fair and transparent:
- Appeal Process: If a contributor feels the AI’s score is off, they can appeal. Moderators and maintainers reviewed and adjusted rewards where necessary.
- Budget for Maintainers: Maintainers have access to their discretionary project’s budget to manually reward special cases or critical but hard-to-measure tasks (like community support or multi-week refactoring).
These checks and balances helped us keep the system fair, transparent, and adaptable to real-world edge cases.
3. What We Learned & Why We Pivoted
Despite good intentions, cracks formed.
Some contributors gamed the system. Communication moved off GitHub to avoid score penalties. PRs were optimized for points—not for real project impact.
But the problem wasn’t the algorithm. The issue was the incentive: when money is involved, people will try to game the system. That behavior is inevitable.

So we made a decision: we’re no longer using the AI agent to distribute grants.
The algorithm we built to evaluate PRs was far more powerful than we realized. It turned out to be incredibly effective at scoring contributors and projects—filtering signals from noise with surprising accuracy.
As open source gets increasingly flooded with low-quality, AI-generated PRs, this capability is becoming essential. We believe this algorithm is a foundational brick for the future—ensuring quality work can still be identified and rewarded.
That’s why we’re putting the scoring engine to work in more impactful ways—fueling a new set of AI-powered tools designed to scale quality, not just quantity, in open source.
4. What's Next: Four AI-Powered Tools
Building on the scoring algorithm’s success, our goal is to scale meaningful collaboration in open source by pairing AI with human insight. Not just in blockchain—but across the OSS landscape. This means:
- A universal contributor ranking system across ecosystems
- A powerful matching engine for aligning talent with the right tasks
- A suite of tools to support maintainers, reduce overhead, and improve collaboration
- An AI-managed Fellowship Program where gaming the system is impossible
Let’s take a closer look:
1 - Quality Scoring
We aggregate metrics like PR complexity, feedback quality, and long-term project impact to generate rich, multidimensional contributor rankings.
By tracking performance across repos and ecosystems, we create universal contributor profiles—rewarding those who tackle complex problems or contribute across diverse technologies.
2 - AI-Powered “Matching Engine”
“Good first issue” filters of GitHub only go so far. Our upcoming AI matching engine goes deeper—using semantic analysis to connect contributors with tasks that fit their skills, learning goals, and work style.
- Technical Stack Analysis By analyzing public code activity (e.g., GitHub, GitLab), the engine builds a technical contributor profile—covering languages, frameworks, and libraries—then recommends matching issues, reducing guesswork.
- Contextual Complexity Matching Instead of just matching tech stacks (“C++ devs with C++ tasks”), the system considers the complexity of past contributions—lines of code, issue history, and problem-solving patterns—to guide experienced devs to advanced tasks and newcomers to mentorship-friendly ones.
- Real-Time Recommendations If a new issue matches your profile and is marked urgent, you’ll get notified instantly—no need to hunt.
3 - Maintainer Tools
Maintainers are essential to open source—but often overwhelmed by boring tasks. Our AI agents aim to ease the load, from reviewing PRs to onboarding contributors, so maintainers can focus on what matters: architecture, mentorship, and community building.
- Automated Contributor Vetting We generate contributor reputation scores by analyzing merged PRs, historical code quality, and social signals—helping maintainers quickly assess who’s likely to stick around.
- Intelligent Code Review Assistance Using LLM fine-tuned to open-source data, our agent can highlight bugs, security risks, and performance issues, while offering context-aware suggestions—like linking code to past architectural decisions or style guides.
- Adaptative Task Assignment New issues are automatically matched with the best-fit contributors based on availability, experience, and track record. Maintainers review only the edge cases.
4 - AI managed fellowship program
We’ve evolved our grants into something more meaningful for top contributors: the OnlyDust Fellowship Program.
Fellows receive $1K–$5K per month for three months to contribute long-term on selected, high-impact open source projects.
But here’s the difference: it’s powered by our scoring algorithm. Instead of sifting through thousands of applications, we use contribution data to surface the most impactful developers. From there, we manually select the top candidates to invite.
It’s merit-based. Signal-driven. And impossible to game.
We’ll also continue to spotlight high-potential projects—helping them gain visibility, build credibility, and move through the funding funnel with real support at every step. Grants will continue to be given just for projects, and just for top ones.
5. Looking ahead: from $11M* to long-term impact
*$10M manually, $1M with AI.
These tools are just the beginning. They’re how we’re translating everything we’ve learned—from $1M in AI-driven rewards to thousands of OSS contributions—into scalable, long-term impact.
We still believe in AI. And we absolutely believe in open source.Our agent now fuels a better mission—empowering humans, not replacing them.
As we refine our models and gather more data, our systems will become more accurate, more contextual, and more useful.
If you're a maintainer, contributor, or sponsor—come build with us.
Our AI tools are evolving. Our mission is clearer than ever.
Ready to contribute? Explore open issues. Want to grow your project? Apply to get it accelerated. Curious about the Fellowship? Follow us—we’re just getting started.
Open source is evolving. Let’s build what’s next—together.